HTML stands for Hyper Text Markup Language. There is a great HTML language reference at W3C working draft that describes the syntax and structure and the semantics of HTML elements and their attributes.
Content is “marked up” using tags to designate the structural significance of that content. Each piece of content so marked up constitute an HTML element, of which there are many.
A first level header is designated by opening and closing tags: <h1> 01 Writing HTML5 </h1>. All parts of the document are marked up with such tags to create HTML elements, even parts that you cannot see but still describe the document, such as the meta tags found in the header, or the <style> and <script> tags that contain CSS and Javascript.
To create an HTML page, open a text processor. Creating a new file and call it index.html when saving. The file needs to be called index.html with a lower “i”. It is the index of the directory in which it is located. It will be the file that is opened upon entering that directory.
Every directory should have an index.html file, as some web servers allow visitors to see the content of the directory when there is no index.html file present. Other files in the directory can be reached by placing links connecting that page on the index.html page.
The following elements make up the HTML page:
The Structure of an HTML Document
The Doctype
The doctype has been greatly simplified in HTML5. The DOCTYPE tells the browser the version of the HTML rules the document will follow. Using the following DOCTYPE tells the browser you will be using HTML5. This is the only DOCTYPE I expect to see.
<!DOCTYPE html>
The HTML Element
The HTML elements contains all other elements. It is the root element, and the language attribute is specified as English.
<html lang="en">
The Head Element
The head element contains information about the content, but not the content itself. This is known as the document;s metadata. The head element does not get displayed in the browser window.
The Character encoding declaration specifies the encoding used to store or transmit the document. The Meta tag charset=”utf-8” tells the browser to use the unicode universal character set transformation format—8-bit.
The title shows up as the title of the browser window.
<head>
<meta charset="utf-8">
<title>Name</title>
</head>
The header element closes before the body element opens.
The Body Element
Markup written in the body element shows up in the viewport, or browser window. Think of this element as encompassing everything that appears in the browser window.
Everything you write comes between the opening and closing body tag. In the following, only “Hello World!” will show. Comments are not rendered by the browser.
<body>
<!-- Comment your Work! -->
<p>Hello World!</p>
</body>
The body element closes before the html element closes.
The Closing HTML element
Closing the HTML element is the last tag on the page. It closes the tag that holds all of the other elements in the document.
</html>
Element or a Tags?
An element is a single “chunk” of code comprising of a start and ending tag. They are representations of a thing for the browser, an object. Elements have all kinds of properties for the browser, like firstChild, etc.
<div>This is a div element</div>
Tags is the opening and closing code of the elements. <div> is a tag. <div>content</div> is an element.
“Elements are not tags. Some people refer to elements as tags (e.g., “the P tag”). Remember that the element is one thing, and the tag (be it start or end tag) is another. For instance, the HEAD element is always present, even though both start and end HEAD tags may be missing in the markup.” From W3 HTML specification
The Inherent Structure of HTML
HTML is concerned with the structure of the content, and not with how the content should be displayed.
The natural flow of content is inline, meaning that content flows horizontally, like the letters on a line of text. In English, that is from left to right, but it could be in any direction.
In addition to the horizontal inline flow of content, elements can be determined to be block like and flow vertically. Block elements do not flow like characters, but like paragraphs, as entire blocks of text. By default, their width expands to fill the parent element and the flow is vertical. They flow down the page, starting from the upper left hand corner.
In HTML, block elements cannot descend from (be a child of) inline elements. Inline elements are the content of a block element.
CSS can change the display property of an element. It can make inline elements display as block elements, and block elements display as inline elements. That is very useful, usually to make inline elements act like block elements.
Valid HTML requires that block level elements do not descend from inline elements. Changing the elements displays with CSS does not change the validity requirements of the HTML document.
Tag Attributes and Values
Tag Attributes
HTML tags can take attributes, which describe certain aspects of the elements, with different elements having various assigned attributes. There needs to be a space between each attribute. Attributes for the img tag, for example, are src, width, height, class, and alt.
Example: <img src ="file_name" alt="logo">
Values
Every attribute has a value, even if it is an empty value. For example, the value of the src (source of the image) is the location and name of the image. While it is no longer a requirement to put either double or single quotes, as long as there are no spaces or other non-alphanumeric characters, it still best practice to do so.
Example: <img src="file_name" alt="logo"> />
Role Attributes
The role attribute describes the role(s) the current element plays in the context of the document. In the official language of the W3 “The XHTML Role Attribute allows the author to annotate XML Languages with machine-extractable semantic information about the purpose of an element. Use cases include accessibility, device adaptation, server-side processing, and complex data description.”
Example: <nav roll="navigation">
Understanding the Tag Hierarchy
HTML is a collection of elements arranged in a kind of containment hierarchy. This is a parent – child relationship, where the enclosing tag is the parent of the enclosed tag, which is its child. The entire structure can be likened to a tree, with the <html> tag as the single trunk from which the rest of the branches arise, first splitting into the two main branches, the <head> and the <body>. inside the body tag are all of the other branches that make up the document.
After the <doctype>, the HTML document starts with the <html> element that contains all other elements. It contains only two tags, the <head> and the <body> tags.
The <head> tag contains information about the page (meta-information), but that is not visible, like the <title> tag, <meta>tags and <html>, <style> and <script> tags and links <link>to styles and scripts.
The <body> tag contains all of the content, everything that’s visible in the browser window. The tags are usually several levels deep. Nesting tags is very useful, for it groups elements together. This makes it easy to create the different parts of the layout.
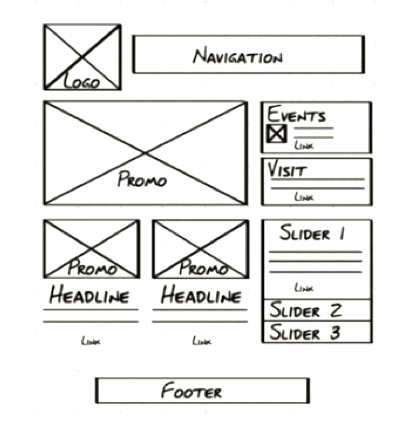
In the figure on the right, the <wrapper> contains all of the other visible content. This element is usually given automatic margins that center it horizontally in its parent tag, the <body>. If the <wrapper> is moved to the right, all the child elements contained within it are moved to the right as well.
Because each element is a child of another element, there are only clearly determined paths. For example, the <img> is a child of <p>, which is a child of <article>, which is a child of <section>, which is a child of <wrapper>. The complete path of the <img> tag is html body wrapper section article p img. This path would select all images in the paragraphs contained in article, section, wrapper, body, html. Since there are no other images, only the image with the red background is targeted by this path. The <img> in the figure has a different path, for example.
How to Write the Code
A tab is used to show how many levels the code is nested from the <html> element. This results in a visual way to check if the code is nesting properly. The code should look like :
<html>
<head>
<title>title </title>
</head>
<body>
<main>
<section>
<header>
<h1>Headline for Page</h1>
</header>
<article>
<p>content
</article>
<footer>
</footer>
</section>
</main>
</body>
</html>
To make it easy on you, there are tools that let you clean up your hierarchies automatically. You’ll want to remember this link right before you hand in your midterm and at the end of the semester, when you hand in your final.
The DOM
The HTML file with all of its codes and content gets parsed by the browser. The syntax of each tag will be analyzed to see how it fits together according to the HTML rules. This results in a document object model where each node represents a branch on the tree.
The nodes drill down into each element to the attributes inside of the tags and to the content of the element. The DOM tree can be seen in this live DOM demo. Paste the HTML5 template into the Markup to test box below to see an example of how the browser parses the tags of a simple document into a DOM tree:
To see the document tree of a more complex example, copy the source code for this page and paste it into the Markup to test box
General Rules To Follow
HTML5 has loosened up the rules somewhat, but it is still desirable to follow these rules for well formed HTML documents.
- Close Every Tag
- Most Tags contain their content, meaning that there is an open tag and a closing tag. Some tags are self closing, like the
<meta>, <link>, <img> and <br> tags. These tags get replaced by the content, in the case of the picture, or cause a line break, in case of the <br>.
Self closing tags should self close, meaning that they end in a /> and all other tags should be closed. Accidentally not closing a tag can cause all kinds of havoc and will be flagged when validating, which you should be doing often in the first few weeks of writing code.
- Correctly Nest Every Tag
- If a tag opens before a preceding one closes, it must be closed before that preceding one closes.
<header><h1>Title</h1></header> not <header><h1>Title</header></h1> CSS relies on proper nesting to target styles to elements, so you have to get this right. In this example, the </h1> tag is nested in the </header> tag, and is the child of the header, which is the parent tag. As a container, a tag acts like a group, and moving a parent also moves all of the enclosed children. Likewise, absolute positioning is based on the coordinates of the parent element.
If you visualize each element as a node on a tree, it is obvious that you cannot open a tag before the previous tag is closed. If you make a mistake, the browsers can sometimes repair the damage, and everything still displays correctly, but don’t count on it, and different browsers have different levels of damage control.
- Inline Tags Cannot Contain Block Level Tags.
- Block-level elements follow one another according to the document flow, one below the other. Inline elements follow one another as characters in a paragraph. While it would seem obvious to not mix these two up, the validator will catch you if you do.
- Keep Tags Lower Case
- This is a requirement of XHTML5, which we will not concern ourselves with, but its a good idea anyway.
Tags Used to “Mark Up” the Content
Learning HTML comes through writing HTML. The more you code, the easier it becomes, till it’s second nature. The content is divided into inline and block tags.
- Inline elements display just like characters, coming one after the other horizontally, till it comes to the end of the line. The line then breaks and resumes at the beginning of the next line down, and so on.
- Block elements display like paragraphs, coming one after the other vertically down the page in the document flow.
Reminder: Just to make it confusing, CSS allows you to override the object’s default display, and make inline elements display like block elements and vice versa.
There are many HTML elementsup.
Inline Elements
These elements display just like characters, coming one after the other horizontally, till it comes to the end of the line.
span
The span tag selects inline content.
So much information.
So much <span style="color: red;">information</span>.
strong
increases importance
So much information.
So much <strong>information</strong>
emphasis
for emphasis
So much information.
So much <em>information</em>
line break
Breaks the line without creating a new paragraph.
So much
information.
So much <br />information.
One Line Quotations
Quotations inside of a paragraph are suppose to get automatic quotes when you use this tag.
So much information
.
So much <q>information</q>.
Anchor Tag (Links)
The anchor element anchors a URL (uniform resource locator, or a unique web address) that targets the destination id or web page by using the href (hypertext reference) attribute.
Any tag can be a target, within any document on the world wide web. To target a tag, it has to contain an id <h3 id="anchor">.
To target the id, you need to use the id identifier, the hash tag # and the id name itself. <a href="#anchor">.
Hyperlink to destination on the same page
Click the example below and you’ll see the page jump just a little.
Hyperlinks to other pages
A hyperlink can address any unique webpage on the world wide web. It can use an absolute address, or a relative address, if the page is on the same server.
Absolute Hyperlink Address
An absolute address starts with http://, as in the address of the page that you are on (look up at the address bar)<a href="http://b.parsons.edu/~dejongo/01-writing-html5/">Writing HTML5</a>.
Relative Hyperlink Address
If the page is on the same server, it is possible to omit the absolute reference, and specify the path to the document from the location of the document containing the link.
Links to a location on the same page are always relative to the page itself.
Targeting tags on other pages
Links to a location an another page come at the end of a absolute or relative address.
and
Image Tag
The image tag gets replaced by the image. That is why it does not have a closing tag. You can make a tag self closing by including the slash mark / right before the greater sign.
You need to specify an alt attribute so that text will appear if the image does not. The title attribute is optional. The title shows up when you hover over the image for a second or more.

<img src="image_location/name_of_image" alt="description of
image for screen readers or when images are turned off" title="Final Thumbnail" />
Comments
Comments are a way to add notes or hide code. Comments are not displayed by the browser. Use them to notate your document with a description of what's going on in each part of the document.
Comments will help remind you why you did something a certain way (or help someone else figure out how to read your code).
You can also use comments to temporarily hide code that you do not want to use, but do not yet want to delete.
Do not use two dashes in a row -- within the comment, as that causes confusion in some browsers.
<!--
Comment your Work!
-->
Block-level Elements
Block elements display like paragraphs, coming one after the other vertically down the page in the document flow.
div
div stands for division, and it is the generic block element. It is used when an element is needed for styling purposes or as a convenience for scripting. Note that it is not equivalent to the HTML5 section element.
content
<div style="background: pink; padding: 10px;">content</div>
Headlines
How a headline looks depends on how they are styled. You should use headlines to structure your content, not based on how they look.
Headline h1
Headline h2
Headline h3
Headline h4
Headline h5
Headline h6
<h1>Headline h1</h1>
<h2>Headline h2</h2>
<h3>Headline h3</h3>
<h4>Headline h4</h4>
<h5>Headline h5</h5>
<h6>Headline h6</h6>
paragraph
paragraph bla bla bla bla.
paragraph bla bla bla bla.
<p>paragraph bla bla bla bla.</p>
<p>paragraph bla bla bla bla.</p>
Block Quote
Used to style quote that takes up an entire paragraph. It is indented and given a different style.
paragraph bla bla bla bla.
So much information.
<p>paragraph bla bla bla bla.</p>
<blockquote>So much information.</blockquote>
ordered list
Ordered lists are numbered sequentially.
Ordered List
- list item
- list item
- list item
- list item
- list item
<h3>Ordered List</h3>
<ol>
<li> list item </li>
<li> list item </li>
<li> list item </li>
<li> list item </li>
<li> list item </li>
</ol>
Continuation of the Ordered List
If you plan on breaking the list into several lists, but want them to be numbered sequentially, use the start attribute start="5". This would start the list at 5 instead of 1.
- list item
- list item
- list item
- list item
- list item
<ol start="6">
<li> list item </li>
<li> list item </li>
<li> list item </li>
<li> list item </li>
<li> list item </li>
</ol>
Unordered List
Unordered lists is for a collection of unordered items, where the order would not change the meaning of the list. It is always used for navigation, with each menu item considered as part of the list. The unordered list is styled to remove the list style.�
- list item
- list item
- list item
- list item
- list item
<ul>
<li> list item </li>
<li> list item </li>
<li> list item </li>
<li> list item </li>
<li> list item </li>
</ul>
Definition Lists
Definition lists is for a list of terms and corresponding definitions. The term to be defined is listed first with the definition coming after the term. A term can have multiple definitions, and a definition can have multiple terms. A definition header can precede the definition.
List Header
- Term 1
- This is the definition of the first term.
- Term 2
- This is the definition of the second term.
<dl>
<lh>List Header</LH>
<dt>Term 1</dt>
<dd>This is the definition of the first term.</dd>
<dt>Term 2</dt>
<dd>This is the definition of the second term.</dd>
</dl>
- term
- definition1
- definition2
<dl>
<dt>term</dt>
<dd>definition1</dd>
<dd>definition2</dd>
</dl>
- term1
- term2
- definition
<dl>
<dt>term1</dt>
<dt>term2</dt>
<dd>definition</dd>
</dl>
table
The HTML table layout mode allows authors to arrange data -- text, images, links, forms, form fields, other tables, etc. -- into rows and columns of cells.
Simple Table
| table cell item |
table cell item |
| table cell item |
table cell item |
<table>
<tr> <td> table cell item </td>
<td> table cell item </td>
</tr>
<tr> <td> table cell item </td>
<td> table cell item </td>
</tr>
</table>
Fully Loaded table
A table can have a head, multiple table bodies and a table footer. You can span both rows and columns with the rowspan="2" or colspan="2" attribute. This allows for the header to expand down and the footer to expand across in the following example.
The Caption Holds the Title of the Table
| Head 1 |
Head 2a |
Head 3 |
| Head 2b |
| table cell item |
table cell item |
table cell item |
| table cell item |
table cell item |
table cell item |
| table cell item |
table cell item |
table cell item |
| table cell item |
table cell item |
table cell item |
|
The footer is a place for information about the table.
|
<table id="table">
<caption>The Caption Holds the Title of the Table</caption>
<col><col><col>
<thead>
<tr><th rowspan="2">Head 1</th><th>Head 2a</th><th rowspan="2">Head 3</th></tr>
<tr><th>Head 2b</th></tr>
</thead>
<tbody>
<tr> <td> table cell item </td> <td> table cell item </td> <td> table cell item </td></tr>
<tr> <td> table cell item </td> <td> table cell item </td> <td> table cell item </td></tr>
</tbody>
<tbody>
<tr> <td> table cell item </td> <td> table cell item </td> <td> table cell item </td></tr>
<tr> <td> table cell item </td> <td> table cell item </td> <td> table cell item </td></tr>
</tbody>
<tfoot>
<tr><td colspan="3">The footer is a place for information about the table.</td></tr>
</tfoot>
</table>
Iframe
An inline frame places another HTML document in a frame. The inline frame can be the "target" frame for links defined by other elements, and it can be selected by the user agent as the focus for printing, viewing its source, and so on.
The iframe is exhibited with attributes that are determined using the equivalent CSS in the demo width: 98%; height: 300px; border: 1px solid #f000; overflow: scroll;.
<iframe src="01-writing-html5/">height=100 width=200 frameborder=1 scrolling=yes >You need a Frames Capable browser to view this content.</iframe>
Writing HTML, Absolute and Relative Addresses, Tools of the Trade
Target iframe from Link
You can target any page to appear in the iframe by naming it and using the target attribute with the name target="iframeDemo" as demonstrated above. Click on the links above to load different documents.
A destination anchor is used to position the Writing HTML document at the iframe section. That requires an anchor with the same name <a id="i-frame">. See the link tag above.
<a href="01-writing-html5/#i-frame" target="iframeDemo" >Writing HTML</a>
<a href="01-absolute-and-relative-addresses/" target="iframeDemo" >Absolute and Relative Addresses</a>
<a href="01-tools-of-the-trade/" target="iframeDemo" >Tools of the Trade</a>
HTML5 tags
Before HTML5, the generic markup elements, <div> and <span>, were used to mark up the page. That means the code itself had no way of determining what the content was.
HTML5 changed that.
HTML5 standardized a lot of best practices to create semantically relevant block level tags that help organize the document. It is now possible to tell header content from the content of an article by looking at the tags alone. The most important of the new elements are: <main>,<section>, <header>, <nav>, <article>, <aside>, <footer>, <figure>, <figcaption>, <hgroup>, <wbr>.
Document Layout
<main>
<section>
<header>
<hgroup>
<h1>Name</h1>
<h2>Name</h2>
</hgroup>
</header>
<article>
<p>content <wbr> content</p>
the <wbr> tag, or Word Break Opportunity tag, is an inline tag that specifies where in a text it would be ok to add a line-break.
<aside>
<p>content</p>
</aside>
</article>
<footer>
</footer>
</section>
</main>
Adding Navigational Links
Using an unordered list.
<nav>
<ul>
<li><a href="#">link to homework</a></li>
<li><a href="#">link to homework</a></li>
<li><a href="#">link to homework</a></li>
</ul>
</nav>
Adding a Picture
With a caption.
<figure>
<img src="example.jpg" alt="example" />
<figcaption> Caption </figcaption>
</figure>
Copy and paste this basic HTML5 template into a blank Textwrangler file. It has most of these elements and a basic header, so you can start coding the content right away. Repetition will acclimate you to writing HTML.

{kind=link}