HTML5 Element Index. Once you click on the tag you want to investigate, click on the code snippet for code you can use or the W3 to go to the specification.
Grouping
HTML5 Element Index. Once you click on the tag you want to investigate, click on the code snippet for code you can use or the W3 to go to the specification.
Complete web site. Styling navigation, site architecture, optimizing the site for search engines and implement Google Analytics to track users. Activity: Build website using HTML5 Boilerplate. Activity: Style navigation links. Activity: Open up a Google Analytics account and apply it to your web pages.
Develop your portfolio website. Read chapter 13. This Midterm Assignment is Due: Next week for review and grade. Have it ready for presentation two weeks from now.
Additional materials for this unit can be found by following these links (30 pages):
The goals of this unit are to:
At the end of this unit, students will have:
| 20 | Review homework and answer questions. |
| 10 | Lecture: Information Architecture (IA) |
| 55 | Demo: Styling the Navigation |
| 10 | Break |
| 15 | Lecture: Search Engine Optimization |
| 15 | Demo: Google Analytics |
| 20 | Demo: The HTML5 Boilerplate (Watch the Video) |
| 10 | Demo: Print Style Sheet and 404 Page. |
| 10 | Lecture:Trouble Shooting |
| 10 | Demo:Adobe Browser Lab and video explanation (you need to sign up to use it) |
These are the terms that participants should be familiar with during this unit:
The 404 or Not Found error message is aHTTP standard response code indicating that the client was able to communicate with the server, but the server could not find what was requested. The web site hosting server will typically generate “404 – Not Found” web page, when a user attempts to follow a broken or dead link, hence the 404 error is one of the most recognizable errors users can find on the web.
Information architecture (IA) is the art of expressing a model or concept of information used in activities that require explicit details of complex systems. Among these activities are library systems, Content Management Systems, web development, user interactions, database development, programming, technical writing, enterprise architecture, and critical system software design. Information architecture has somewhat different meanings in these different branches of IS or IT architecture. Most definitions have common qualities: a structural design of shared environments, methods of organizing and labeling websites, intranets, and online communities, and ways of bringing the principles of design and architecture to the digital landscape.
User interface design or user interface engineering is the design of computers, appliances, machines, mobile communication devices, software applications, and websites with the focus on the user’s experience and interaction. The goal of user interface design is to make the user’s interaction as simple and efficient as possible, in terms of accomplishing user goals—what is often called user-centered design. Good user interface design facilitates finishing the task at hand without drawing unnecessary attention to itself. Graphic design may be utilized to support its usability. The design process must balance technical functionality and visual elements (e.g., mental model) to create a system that is not only operational but also usable and adaptable to changing user needs.
Interface design is involved in a wide range of projects from computer systems, to cars, to commercial planes; all of these projects involve much of the same basic human interactions yet also require some unique skills and knowledge. As a result, designers tend to specialize in certain types of projects and have skills centered around their expertise, whether that be software design, user research, web design, or industrial design.
Principles of User Interface Design are intended to improve the quality of user interface design. These principles are:
Google Analytics is a free service offered by Google that generates detailed statistics about the visitors to a website. Google Analytics gives you rich insights into your website traffic and marketing effectiveness.
You add a JavaScript snippet onto every page of your website. This code collects individual visitor’s publicly available data, like which ISP they use and what kind of machine and browser, how long they stay on your site, which page they landed on, how they got there, etc., and sends it back to Google data collection servers for processing. It also sets a cookie on each visitor’s computer used to store anonymous information such as whether the visitor has been to the site before (new or returning visitor), what is the timestamp of the current visit and what was the referrer site or campaign the visitor came from e.g. search engine, keywords, banner or email.
Google Analytics does not work if the user disables its cookies.
Signup to Google Analytics using your Google account. You will need your Website’s URL to create an account.
Once you sign up, you will receive a javascript snippet to put at the bottom of each page on your site that will do all of the work. Do not copy this one, as each page tag is site specific, and you have to sign up to get your own. You will already have this set up in the HTML5 Boilerplate. All you need is the account number (highlighted in yellow).
<script type="text/javascript">
var _gaq = _gaq || [];
_gaq.push(['_setAccount', 'UA-XXXXXXXX-1']);
_gaq.push(['_trackPageview']);
(function() {
var ga = document.createElement('script'); ga.type =
'text/javascript'; ga.async = true;
ga.src = ('https:' == document.location.protocol ?
'https://ssl' : 'http://www') + '.google-analytics.com/ga.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ga, s);
})();
</script>
Paste the code right above the closing </head> tag.
Once you have signed up, and have inserted the page tag at the bottom of each of your web pages, you can watch how many visitors come your way (there is a 12 hour delay, or so). The program was originally developed to track ads, but it can do a lot more than just look at who is visiting your site. You can use the service to see which pages perform and are catching the users’ attention, and which pages do not, allowing you to optimize the web site according to real world usage feedback.
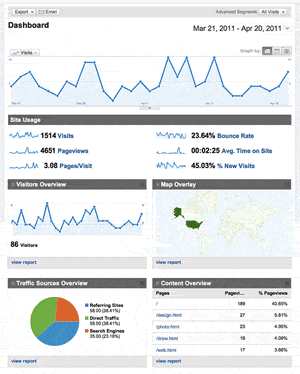 To make it easier, Google Analytics has a dashboard to see the most pertinent statistics like site usage, visitor information and where they came from.
To make it easier, Google Analytics has a dashboard to see the most pertinent statistics like site usage, visitor information and where they came from.
You can track if the visitor is new or returning, how long they spend on each page or the site as a whole, what browser they are using, who their provider is, which page they enter and exit and from where they came from, and if a search engine was used, which one and what the search query was.
You can tell what language does the visitor uses and their country of origin. Check out the list of keywords and drill down to see how effective they are. With the interactive In-Page Analytics, you can see the statistics as they relate to individual pages of your website.
It is possible to isolate and analyze subsets of your traffic, and compare segment performance side by side in reports. You can save reports that present the information you want, and it even tracks changes in usage data patterns, but all of that is beyond the scope of this introduction.
Google Analytics is a great tool and needs to be explored in depth by everyone creating web sites. Though Google is ubiquitous, there are alternatives, like Woopra or Piwik. Microsoft has a somewhat similar service.
Your best chance of gaining top honors in google’s site ranking is creating a high quality web site. In their most recent Google Search release, called the panda algorithm, Google provided guiding questions that helped them shape how their search engine should work. It’s only logical that these questions also work as a guide to how to built the web site that ranks well in the first place. Here are those questions:
Now you know what Google thinks a quality site is. Most of the questions have to do with the copy, and not the pictures. Though search engines are not completely blind to pictures, they do not evaluate your fabulous pictures and designs. Take that into account and judiciously use the alt attribute to translate pictures into words.
The search bots crawl links, essentially discovering the link structure of the web that binds all pages. The search engine then analyses the code and stores selected pieces of the pages in massive hard drives, to be recalled when you make a search.
The search engine does two things for the user: it returns only those results that are relevant or useful and ranks those results in order of importance, usually according to popularity.
The best advice that Google gives is to build the web page in a standards complient and semantically correct way. Search Engine optimization, or SEO means to build web pages so they are optimally structured for search engines.
Indexable content: Search Robots only read text. All non-text should have detailed descriptions, as in alt attribute for pictures, descriptions for Flash and Java plug-ins and video files should have transcripts between the audio and video tags if you want people to search for the content. Search engines also need to access the crawlable link structure to find all of the pages on a website.
Keywords are the building blocks of SEO and all search is based on keywords. As the engines crawl and index the contents of pages around the web, they keep track of those pages in keyword-based indices. Search engines have millions and millions of small databases, each centered on a particular keyword term or phrase. This makes it possible for the engines to retrieve the data they need in a mere fraction of a second.
Though keyword usage and targeting are only part of the search engines’ ranking algorithms, effective keyword usage will go far to make pages SEO “optimized.”
Meta tags provide information about a website’s content. You can use the following meta tags: index/noIndex, follow/noFollow and noArchive if you want to talk to the bots directly. The meta description tag draws readers to your site from the results and is an important part of search marketing. This is what gets posted in the description.
The meta keywords tag had value at one time, but is no longer valuable or important to search engine optimization.
Your universal resource locator, or web address, is of great importance from a search perspective.
If you do not want a bot to follow a link, you can include the attribute: rel=”nofollow” after the href, <a href="#" rel="nofollow">link</a>.
If you do not want to be in the search engines, you can place the robots.txt file with the content: User-agent: * Disallow: /in your directory. The * means all user agents, and applies to all bots that search engines use to comb the net. All major search engines respect this convention.
Follow the link to an extensive list of resources that can be applied specifically to landing page optimization.
Step Zero – Really Understand Your Target Market
Step 1 – Set Up Actionable Analytics
Step 2 – Make Sure Your Ad’s Message Matches The Landing Page
Step 3 – Evaluate Your Landing Page’s First Impression
Step 4 – Does Your Page Have Emotional Resonance?
Step 5 – Craft A Clear & Compelling Value Proposition
Step 6 – How Will Images Reinforce The Message?
Step 7 – Should We Create an Explainer Video?
Step 8 – The Importance of Social Proof, Authority & Testimonials
Step 9 – Does The Copywriting Make You Want To Read More?
Step 10 – Does Your Call To Action Communicate Clearly?
Step 11 – Start A/B Testing
So much of a visitor’s landing page experience happens in less than a second & most of focus on the entirely wrong side of that experience.
If you think of your landing page as a way to tell the story of how your prospect’s life gets better, and use what you know about how the brain processes text and images, you can create a “hook” that gets them wanting more.
In that case, Landing page optimization is just a way to make the story better every time it’s told.
Much of this information has come from SEOMOZ, Google’s SEO Starter guide (pdf), Google’s webmaster tools and help and Search Engine Land web site. Visit these to learn perfecting keyword targeting on-page optimization..
Another great resource is the SEO plugin for WordPress Yoast and the site itself has lots of information as well. With all of these resources, there is no reason that your site is not SEO friendly.
Google’s Publisher’s Plugin for WordPress
Visit the Google search algorithm changes chart for 2013 to give you an idea of how a search engine remains a moving target.
We take for granted that we are styling the web site for the screen, but we should not forget that its also important to create a style sheet for when a user prints the web site. You can imagine that a potential client can print out a page from your portfolio to show to someone else at a meeting for a potential treatment of whatever project they are working on.
The most useful thing is to remove some of the clutter. When a user prints a page, they do so for the content. Do them the favor and hide all that is not necessary. The footer, navigation and other unnecessary elements can be set to display: none; . The remaining elements often need their screen styles neutered, and the properties have to be rewritten to clean up the print style. The browser itself applies a print style to the page, removing the background, etc, and the HTML5 Boilerplate has print stylesheet, but you still may need to tweak it yourself.
Add your additions to the print styles at the bottom of the page in the boilerplate:
/* ================================================ Print styles. ================================================ */
Fonts are often larger on the screen than in print, so set the font to serif 12points in size: p { background: white; font: 12pt/14pt "Times New Roman",Georgia,Serif; } and h1, h2, h3, h4, h5, h6 to appropriate sizes.
It is likely that the page is horizontally laid out for a screen. You may want to rearrange the elements vertically for the printed page.
Information can be added by using the content attribute before the header, for example, so you can customize the printed page: header:before { content: "Contact artist for more info, telephone number, email and website, etc"; } or anything else you want the printout to have.
It’s possible to print out the actual link address after the links using a:link:after, a:visited:after { content: " (" attr(href) ") "; } but that prints out all links, so you may want to limit that to to the article tag. This is already taken care of for you in the boilerplate.
Check to see how your page prints out, and add styles to the print section of your CSS style sheet if needed.
Anchors make the Word Wide Web. These hyperlinks are the essence of the web, so styling them is no small matter. They play the central roll in information architecture and user experience design; everything depends on the navigation and what it looks like, and that is what we look at here.
Pseudo-classes affect the document as if — and this is what makes them pseudo — they add a class to the document. The document will display that whether or not a a:link has been a:visited or not, based on the browser history.
The other three pseudo links indicate interactive feedback. The a:hover link applies while the user is over the element with the cursor, the a:active pseudo-class applies while an element is being clicked on by the user.
Notice that a:hover and a:activehave be placed after a:link and a:visited otherwise the cascade can hide their color property. To avoid that, make sure to write them in the order you see here, for it makes a difference.
<a href="#key" accesskey="a">Click Me or press Control-Option-a</a> anywhere in the document.
The a:focus pseudo-class applies to an element that accepts a keyboard event. It is not widely used. There is no feedback in Safari, but Firefox and Opera show that you have pressed the key before executing the link. In Safari you hold down both control and option and the key, in Firefox, just the control button and the key, in Opera, you press shift escape and then select the key and in Internet Explorer, the alt key. In case you want to include keyboard access, you need to add the attribute and the key to the link element, like this: accesskey="a".
It was decided a long time ago that menus are really lists, and should be wrapped in a list to be semantically correct. The code for most of these demonstrations use the following code:
<ul> <li><a href="#">Home</a></li> <li><a href="#">Topic 1</a></li> <li><a href="#">Topic 2</a></li> <li><a href="#">Topic 3</a></li> <li><a href="#">Topic 4</a></li> </ul>
Which, when it has no CSS styling, takes the default look:
The remaining sections will use CSS to style what are otherwise lists of menu choices.
The most obvious CSS changes to the menu are to give it a color (color: white;), to remove the underline (text-decoration: none;), to give it a background (background: orange;), a border (border-left: 5px solid a00;), padding (padding: 42px 0px;), and margins (margin: 5px 5px;). You can use the pseudo classes to target the hover, active and visited states with different attributes, so that the user gets feedback when they go over, click or have visited that link.
You can change the list item li that creates the menu to be either vertical or horizontal by changing its display from display: block which is the default and renders the list vertical to display: inline-block;. This creates a horizontal menu.
If the <ul> is displayed as a table, then the <li> can be displayed as a table-cell. That also creates a horizontal menu. Changing the display to table-row makes the menu vertical.
Floats can also be used to layout the list. Just float all of the <li>s left. You have to remember to clear: left the that follows the list, but otherwise it works well. To make this horizontal, reduce the width of the <ul> to 100px. If you want two rows going down, change the width to 185px.
Now buttons with the CS3 goodness have come a long way, but when the menu needs more pizzaz than even CSS3 can provide, you turn to pictures, so when you hover over a link, the picture changes. This is easily accomplished in CSS using a single image divided into three, where the first part is what you see as a link, the second part is what you see when you hover over, and the third part is what you see when you click the link. The picture looks like this:

The picture is simple enough, with a folder in three colors. The strategy is to show only the first icon, and with each state, move the picture so that it shows a different icon. That way, its blue, red when rolled over and green when clicked. If you want to tell the audience that they have clicked the link before, you can add a forth icon. The HTML is an empty anchor tag <li><a href="0"></a></li>.
Because screen-readers cannot read anything from a picture, it’s necessary to put in a title. You get a popup after a second or so of hovering, with the title on it. <li><a title="link to Home" href="#"></a></li>
To have three pictures on an image and to seamlessly move between them is called an image sprite. It works very well for one link, and it works even better when there are more links, as in the following example with three variations per link for four links on one image file. Each pseudo class calls up the same image but at a different position, using the background-position: no-repeat 0 0 property to easily indicate where the pictures are on the image. The first number after no-repeat is the horizontal (x) offset, and the second is the vertical (y) offset. You can easily get this information from PhotoShop or Illustrator, but that still quite a chore.
To make this process even easier is Sprite Cow, which can take an image with lots of sprites on it, and easily provide you with the code containing the coordinates that makes this process a snap. Take the following image, load it into Sprite Cow, click on each image and copy and paste the coordinates into your stylesheet. Once you get the idea, you’ll never go back.
Since it is necessary to target each link individually, every link gets its own id.
Every time that the browser has to request an image from the server, it takes time, not only for the image to download, but for the server-request. In fact, the server request can take more time than the downloading of the image. The ability to gang up all of your web pictures into one image is for that reason, a real time saver and significantly speeds up the loading of a web page.
As the process for doing so is exactly the same, using Sprite Cow, we do not need to go into a sprite / background image demonstration, as we have covered a lot of ground already, but be prepared to combine all of the smaller pictures into one large image like this for your final web site.
While drop down menus are not really appropriate for small web sites of the kind that you will build here, I include a demonstration of a CSS only drop down menu just in case you do not feel complete if you do not have one, or better yet, build a really big site.
<ul id="nav"> <li class="current"><a href="#">Home</a></li> <li><a href="#">Menu_A</a> <ul> <li><a href="#">Menu_A-1</a> <ul> <li><a href="#">Menu_A-1-a</a></li> <li><a href="#">Menu_A-1-b</a></li> <li><a href="#">Menu_A-1-c</a></li> <li><a href="#">Menu_A-1-d</a></li> </ul> </li> <li><a href="#">Menu_A-2</a> <ul> <li><a href="#">Menu_A-2-a</a></li> <li><a href="#">Menu_A-2-b</a></li> </ul> </li> <li><a href="#">Menu_A-3</a> <li><a href="#">Menu_A-4</a> </ul> </li> <li><a href="#">Menu_B</a> <ul> <li><a href="#">Menu_B-1</a> <ul> <li><a href="#">Menu_B-1-a</a></li> <li><a href="#">Menu_B-1-b</a></li> <li><a href="#">Menu_B-1-c</a></li> </ul> </li> <li><a href="#">Menu_B-2</a> <li><a href="#">Menu_B-3</a> <li><a href="#">Menu_B-4</a> <ul> <li><a href="#">Menu_B-4-a</a></li> <li><a href="#">Menu_B-4-b</a></li> <li><a href="#">Menu_B-4-a</a></li> <li><a href="#">Menu_B-4-b</a></li> </ul> </li> </ul> </li> <li><a href="#">Menu_C</a> <ul> <li><a href="#">Menu_C-1</a> <li><a href="#">Menu_C-2</a> <li><a href="#">Menu_C-3</a> <ul> <li><a href="#">Menu_C-3-a</a></li> <li><a href="#">Menu_C-3-b</a></li> </ul> </li> <li><a href="#">Menu_C-4</a> <li><a href="#">Menu_C-4</a> <ul> <li><a href="#">Menu_C-4-a</a></li> <li><a href="#">Menu_C-4-b</a></li> <li><a href="#">Menu_C-4-a</a></li> <li><a href="#">Menu_C-4-b</a></li> </ul> </li> </ul> </li> </ul>
Everyone of you will run into problems, and more than likely, lots of problems, and you have to tackle them one by one, for usually becomes a mess if there are too many problems all at once. The solution, then, is to solve the problems one by one, until they’re all gone. In part 1 of this document shows how to isolate the problem so that you can solve it, and in part 2 provides some clarification on confusing issues in CSS.
The first step is to copy and paste the basic HTML5 code into your text editor and to give it a page a name that contains no spaces and ends with .html. You add a link to an external CSS style sheet in the header of the document and include the CSS reset at the top of your external CSS style sheet.
In an ideal world, you add code and validate every few minutes, staying on the strait and narrow path. This is a lot better than running into a problem and finding out that you have 153 errors because you forgot to validate regularly. Yes, using HTML and CSS is really problem solving. You follow the rules, and each one of them is very simple, but add them all together to create a complicated layout, and that is were the trouble begins.
One way to keep trouble from your door is to organize your document into regions, like a wireframe, diving up your page into independent locales. That way, if there is a problem you know where it is.
It is a good idea to use comments <!-- comments --> or inside of the external style sheet /* comments */ to identify what the code is doing. It is amazing how much we forget when asked to redo something on a job that was done a year ago.
It is also possible to “comment out” parts of the code you temporarily want to suppress, which means that you use this comment code to remove the HTMl markup and CSS rules that you want the browser to ignore.
There are times when you have been busy coding and whatever you are trying to do just does not work. When a document becomes complicated enough, fining an unclosed div can be a problem. That’s when you have to troubleshoot the document.
Troubleshooting comes into play when you have trouble but you do not know the cause of that problem, so you have to figure out where in the code the trouble is, and then fix the problem.
Unfortunately the problem is not blinking on and off so as to attract your attention. Instead, you have to hunt it down.
This becomes more difficult if you have not been validating regularly. It can even happen with pages that do validate, though that is much less likely, so I ask you to validate your documents regularly.
Tools like Firebug, Web Developer and the Inspect Element in the Safari and Chrome browsers can be very helpful. In the last two browsers, right-click on an element and inspect element is the last item in the popup menu. You can activate this inspection and debugging tool in the preferences.
These tools allow you to inspect your CSS, but that does not always indicate what is causing the problem. You might have written the HTML markup or CSS rule incorrectly somewhere else.
If you think that your problem is with one or another CSS definition, start testing them by adding something obvious, like background-color: red;, outline: 1px solid green or something like that.
If you still cannot locate the problem, start removing the rules one at a time, until you find where the problem is. The same is true of the HTML, in case you cannot find the tag that’s not closed, misspelled, etc. You sometimes have to remove a lot, and you can speed up the process by eliminating half, testing it, and if the problem goes away, test the other half, and so on.
Once you have found what causes the problem, you can fix it, circumvent it, etc.
Key to working on the web, especially as you are starting out, is to validate often, as it will let you know as soon as you have gone off track, so please use this service often!
Unicorn Validator for HTML5 and CSS3 and the Regular Validator
This is taken from CSS-tricks.com, one of the great websites to go to.
If you’re a pro, it’s easy to forget the confusion you felt when you just started learning CSS. Just for fun, let’s try and remember some of those little weird confusing moments. I’ll start us out by listing some random ones I remember and have picked up on while helping others recently. Then you folks take it from there in the comments.
These aren’t huge big things like broken layouts in IE or which vendor prefixes should you be using. It’s the little fundamental stuff, like tiny differences in syntax that change meaning in a big way.
What’s the difference between these two things?
.class { }
p.class { }The first one will select any element with that class name. The second one will only select paragraph elements with that class name.
The first is more generically useful. The styling you apply with that class may be useful to multiple types of elements. Even if it’s not today, it might be tomorrow. It’s also faster for the browser to understand and apply.
It’s a fairly rare case that you’d want to use the second example. It would only be if you wanted to re-use the same class name for multiple elements but have them to different things.
p.stand-out { background: yellow; }
span.stand-out { font-weight: bold; }Why are these so different?
.class div { color: red; }
div.class { color: green; }The first example there is very different because of the space character between .class and div. The stuff before the space and the stuff after the space select different elements. The first part is “select any element with this class name” and the second part is “select any div”. Put them together with a space and you get “select any div that is a descendant of any element with this class name”.
The second doesn’t involve any of that descendant business. It’s a tag-qualified selector like discussed above.
If the above CSS was the only CSS on the page, the results would be like this:
<div class="class">
<h2>
<div>Would be red</div>
</h2>
<div>Would be red</div>
Would be green
<div>
<div>Would be black</div>It seems like as far as CSS is concerned, using classes and using ID’s is the exact same thing.
#id { color: red; }
.class { color: green; }It’s just an attribute and it’s a seemingly arbitrary difference in syntax depending on which one you use. The results are predictable:
<div id="id">Would be red</div>
<span id="id">Would be red</div>
<div class="class">Would be green</div>
<span class="class">Would be green</div>You might have learned ID’s are “supposed” to be unique, as in, only have one element per page that uses it. But you’ve slipped up before and it doesn’t seem to matter, the CSS applies just fine.
Then you start getting conflicting information. Some tools and philosophy) teach that ID’s aren’t good for styling. Some articles tell you they are the most efficient. Perhaps you work with a JavaScript developer who tells you they need ID’s on everything because it makes their job way easier.
Confusion abound here. Turns out, everybody is kinda right. Here are the facts:
My personal philosophy is to use ID’s on stuff that I absolutely know there will only ever be one of and will not benefit from properties from a class name shared with other elements.
What’s going on here?
div { color: red; }
div:hover div { color: green; }:hover is a selector which only applies itself when the mouse is over a particular element. What is weird here is that you don’t necessarily have to apply styles to that element being hovered over. In this case, we are applying styling only to descendant divs when the parent div is hovered. So:
<div>
I will be red all the time
<div>
I will be red, unless that top
div is hovered (but not necessarily me)
and then I'll be green.
</div>
I will be red all the time
</div>This:
div{color:red}Is the exact same as:
div {
color : red
}You do need spaces in selectors to make decendent selectors (e.g. ulli { } is absolutely not the same as ul li { }) but other than that you should use whitespace however makes looking and working with your CSS comfortable.
Notice the missing semicolon on that property in the example above. You can omit that if it’s the last property in the group. Personally I never do as if you add more property/values later and forget to add the semicolon to the previous line, that’s a problem. Because whitespace is so free, it will continue to read the next line as part of the value of the previous line.
Example of the problem:
div {
-webkit-border-radius: 10px
-moz-border-radius: 10px
border-radius: 10px
}The whitespace is fine. The no-semicolon on the last one is fine. But the first two property/value pairs don’t have semicolons and will totally screw up and not work.
What font-size is the div going to have?
div {
font-family: Sans-Serif;
font-size: 18px;
font-weight: bold;
font-style: italic;
color: red;
margin: 0 0 20px 0;
font-size: 21px;
padding: 10px;
}It’s going to be 21px. You’ve accidentally listed it twice and the second one is going to win.
If you have two selectors that have the exact same specificity like this:
.red { color: red; }
.green { color: green; }And then they apply to the same element, the selector later in the CSS will always win. Class name order in HTML doesn’t matter:
<div class="red green">Will be green</div>
<div class="green red">Will be green</div>The previous example used “red” and “green” as class names. That’s not very semantic. Why not? That’s a whole ball of yarn, for next week!
We started out the semester with a plain HTML5 template. But not all browsers understand HTML5 (or CSS3). There are old browser you really do not want to know about. Then there are a lot of good things that we could do underneath the hood, like automatically compressing files, etc.
Though it makes your development life a little more complicated, it automatically takes care of the many contingencies that make building a professional website much more difficult.
We are using the HTML5 boilerplate 5, and I expect everyone to use it as the basis for the midterm. Watch the Video
The boilerplate is everything for everybody, from the novice to the professional, so it’s stacked.
Check out the HTML5 Boilerplate Showcase.
Click the DOWNLOAD button.
Take a look at the table of contents. This documentation is bundled with the project, which makes it readily available for offline reading.
There is comprehensive documentation. Learn more about HTML5, browser compatibility, javascript libraries and all the other goodies that make up this boilerplate so that you can extend and customise the HTML5 boilerplate. This is a great learning resource for advanced students.
Enter your CSS code on the external style sheet provided. It is already linked to the index.html page.
The CSS style sheet normalizes the browser in a more nuanced way than the browser reset. These have to come before your own user styles, which are entered in the middle of the document after these instructions:
/* ========================================================== Primary styles Author: ============================================================ */
If you put your declarations in these commented-out instructions, your code will also be commented-out. I’ve seen that happen before, and the student came up to tell me that the template does not work. I’ve also seen students use the index.html page by itself. That also does not work. Keep the folder intact.
After the user styles there are a number of preset styles that can be called to perform a number of tasks. You want these to remain intact after your styles.
All you have to do is create your styles in this middle Primary Styles Author section. and ignore the rest of the style sheet if you do not understand what it does.
Once again, ignore everything that you do not understand.
put the title of the page between the title tags:
<title></title>
Next enter a description of the page/site:
<meta name="description" content="">
Fill in the author:
<meta name="author" content="">
As long as you did not change this name of the style sheet, the default link should work.
<link rel="stylesheet" href="css/style.css">
Enter all of your HTML replacing the code below
Ignore everything else that you do not yet understand.
Hello world! This is HTML5 Boilerplate.
Google Analytics code is already in place. You already have an id if you signed up and followed the instructions . You need to replace “UA-XXXXX-X” with your account number. This way the page is tracked by google’s analytic software, and you can check up on who visits you, how long they stayed, which pages they navigated and more.
var _gaq=[['_setAccount','UA-XXXXX-X'],['_trackPageview']];
Work on the index file till you have made it just like your Photoshop comp / wireframe, with everything as you want it.
Include in this file a styled navigation with links to all of the files that you wish to target. Examples are about.html or bio.html, drawing.html, etc.
When you feel you have achieved this to the point of perfection, duplicate the index.html file and rename each copy to the appropriate page name that you specified in the navigation. This way the site is almost already build as soon as you finish the first page.
This is not much more complicated than before, as long as you can ignore some of the extra code.
Just know that your HTML5 and CSS3 will be more compatible with other browsers than if you did not use this template. That said, if anyone wants to learn this stuff, I recommend going through this boiler plate carefully, read the documentation, and follow all of the links, for you will learn a lot.
You are given a choice, to download the standard HTML5 Boilerplate, which is what we will do in class.
The other option is to get a custom build template.
If you decide on customizing it, get the Bootstrap version. Read all about it. Bootstrap has many goodies built in to make your site will look and work professionally.
Follow the instructions in Google Analytics to get a google analytics account number. Place that number in the index.html file.
Building a standards compliant website with good content is best for search engine optimization. The problem many of you will face is that all your work is composed up of pictures. Search engines prefer words. Make sure that you describe your pictures will in accompanying text or use the alt tag to let the people who use search engines reach your pictures.
The HTML5 Boilerplate is shipped with a lot of things to make life better, but one thing trips the school server, and you need to take it out.
If you drag the entire folder over, you will include the invisible file “.htaccess”. The operating system hides it from you on your computer, but it will transfer that file, and that file contains the instruction Options -MultiViewsthat has to be removed.
If you do not take it out, you will see, when you go to the directory:
The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there was an error in a CGI script.
If you think this is a server error, please contact the webmaster.
Locate the file in the folder using Fetch, edit it, and search for Options -MultiViews , delete it, and save the file.
That should fix the problem.
In-class Demo for both 9:00 and 12:00 classes. You can download them as well.
The design of the demo was directed by students, exploring problem solving as we went along.
You are given a choice, to download the standard HTML5 Boilerplate, which is what we will do in class.
The other option is to get a custom build template.
If you decide on customizing it, get the Bootstrap version. Read all about it. Bootstrap has many goodies built in to make your site will look and work professionally.
For the demo in class, we download the regular HTML5 Boilerplate.
Follow the instructions in Google Analytics to get a google analytics account number. Place that number in the index.html file.
Building a standards compliant website with good content is best for search engine optimization. The problem many of you will face is that all your work is composed up of pictures. Search engines prefer words. Make sure that you describe your pictures will in accompanying text or use the alt tag to let the people who use search engines reach your pictures.
The HTML5 Boilerplate is shipped with a lot of things to make life better, but one thing trips the school server, and you need to take it out.
You will not see this file on your computer, but once you have uploaded the files to the school server, you will see a file called “.htaccess.” This file contains the following line that needs to be taken out:
# ---------------------------------------------------------------------- # Prevent 404 errors for non-existing redirected folders # ---------------------------------------------------------------------- # without -MultiViews, Apache will give a 404 for a rewrite if a folder of the # same name does not exist. # webmasterworld.com/apache/3808792.htm Options -MultiViews
This trips up the server, and you will see a page for error 500.
Server error! The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there was an error in a CGI script. If you think this is a server error, please contact the webmaster. Error 500 a.parsons.edu Apache/2.2.3 (CentOS)